| |
Digression
Though a valid parse given the grammar, arguably, the above tree makes
little sense -- what does it mean to see something with a statue? It
is as if "with a statue" qualifies the "seeing". (Sort
of like "with horses"
as an adverb, which originated when my we saw a sign saying
"DANGER WITH HORSES" and construed it so that it meant "extreme danger").
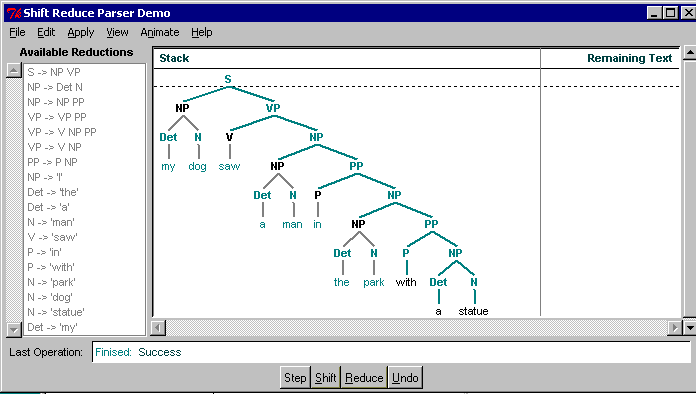
If we do the shift > reduce resolution at different places
in the parse, namely, as steps 13 and 20, the result will make
more sense to a human:
|
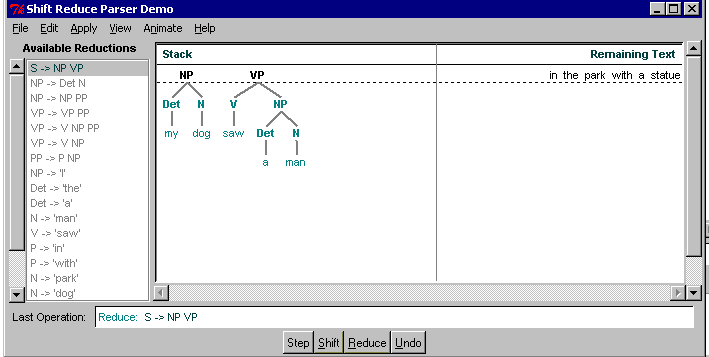
 This is because after the
parser decides to reduce S => NP VP
as step 14. Here is the state of the parser after step 13, just before
wrongful reduction:
This is because after the
parser decides to reduce S => NP VP
as step 14. Here is the state of the parser after step 13, just before
wrongful reduction:
 After correcting this by forcing the parser to shift
as step 14, it fails to parse again, ending
in the following state:
After correcting this by forcing the parser to shift
as step 14, it fails to parse again, ending
in the following state:
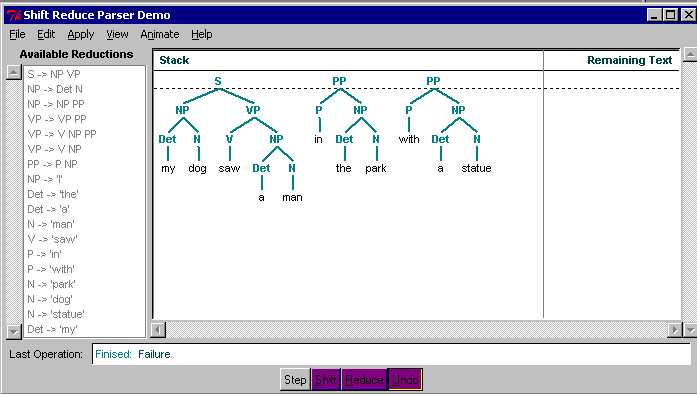
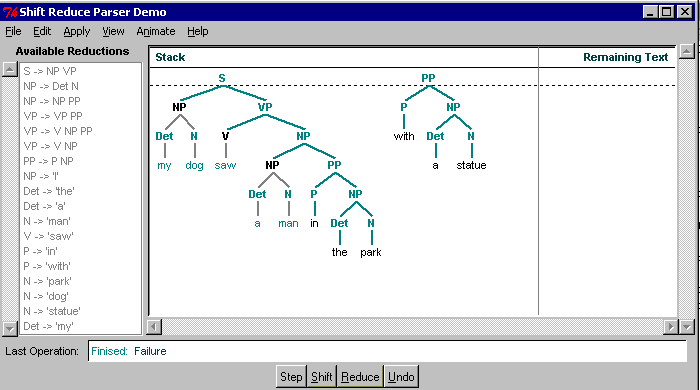 This time the culprit is the choice to again reduce instead
of shifting as step #23. Here is the state after 22
steps.
This time the culprit is the choice to again reduce instead
of shifting as step #23. Here is the state after 22
steps.
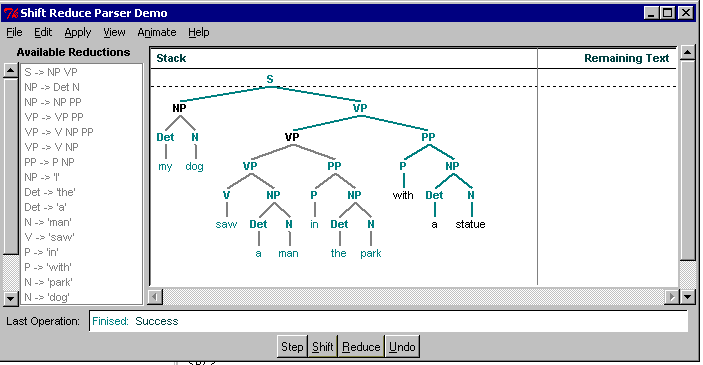
 Forcing step 23 to be a shift generates the correct parse:
Forcing step 23 to be a shift generates the correct parse:
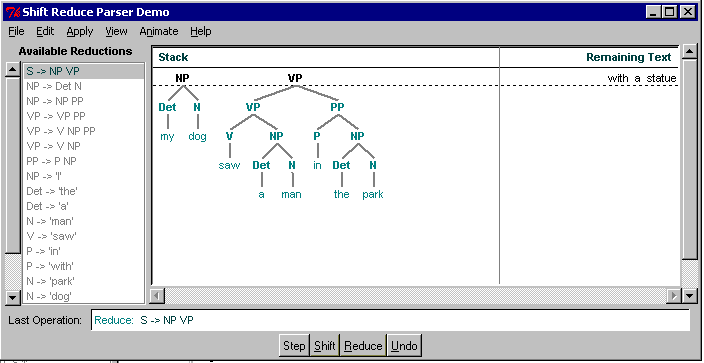
 If we shift here, we will never be able to create the NP
"my dog"; "my" will forever be "hanging". In fact,
since one can always shift (unless end of input has been
reached), one will not reduce anything until it's too late:
If we shift here, we will never be able to create the NP
"my dog"; "my" will forever be "hanging". In fact,
since one can always shift (unless end of input has been
reached), one will not reduce anything until it's too late:
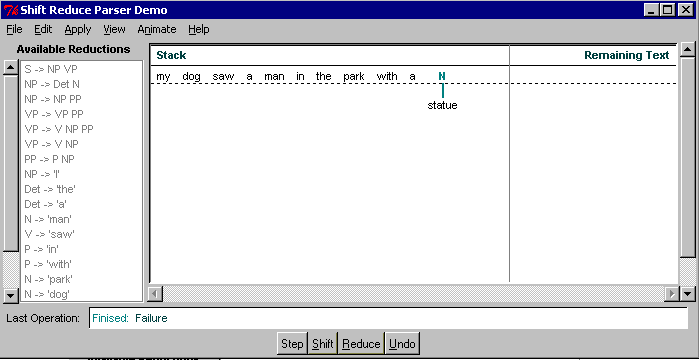
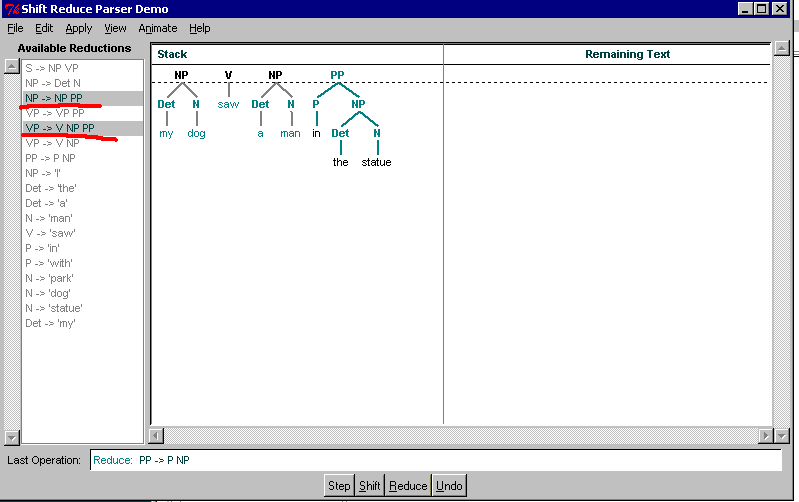 This conflict occurs after step 20, (but
on the way here we have to manually resolve S/R conflict
in step 13 in favor of Shift).
This conflict occurs after step 20, (but
on the way here we have to manually resolve S/R conflict
in step 13 in favor of Shift).
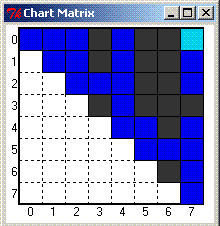
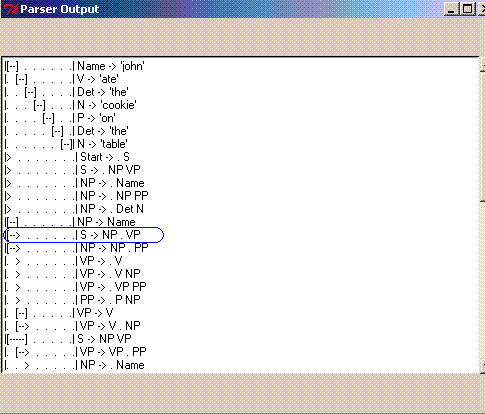
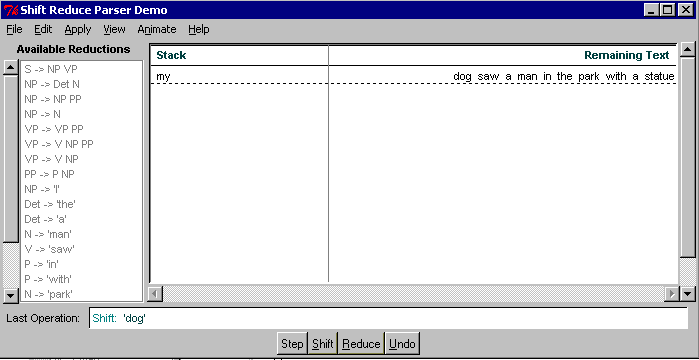
 This split stems from the edge shown in the snapshot below,
circled in blue:
This split stems from the edge shown in the snapshot below,
circled in blue: